Important Note
Important Note:#the timeline for whole process(failover/failback is 15mins)Important Note
Take screenshot before and after Failover/Failback
Safety:#Take screenshot of virsh list --all with date from all servers before starting the process and after the process 1.check ram on each server before starting the process free -h 2. The sequence while starting the vms should be i. registry ii. nfs iii. master nodes iv. worker nodes 3. While checking the rbd image status of libvirt of vms on both the DR site and PR site , check if any vm is behind master 4. Very Very important to note that you must NOT promote the image until image status shows as non-primary on the site where you have demoted. So once you have issued demote command, keep checking image status till we see non-primary, after that only come back to the actual site and promote the images. If any image get stuck for sometime (2-3 minutes) then call me immediately as we cannot proceed further and there is serious risk of disks getting damaged if image is promoted before it was marked non-primary after demotion.Overview
This runbook guides you to fail over services from DR to PR safely. Follow sections in order. Commands are grouped and copyable.
Plain English: We first pause automations, ensure storage mirroring is healthy, shut down DR, switch image ownership (demote DR, promote PR), then bring PR VMs up in phases and verify apps.Pre-checks
Confirm Ceph RBD mirroring and services.
# Check pool mirroring status rbd mirror pool status libvirt-integ-pool # Restart RBD mirror service if needed sudo systemctl restart ceph-rbd-mirror@admin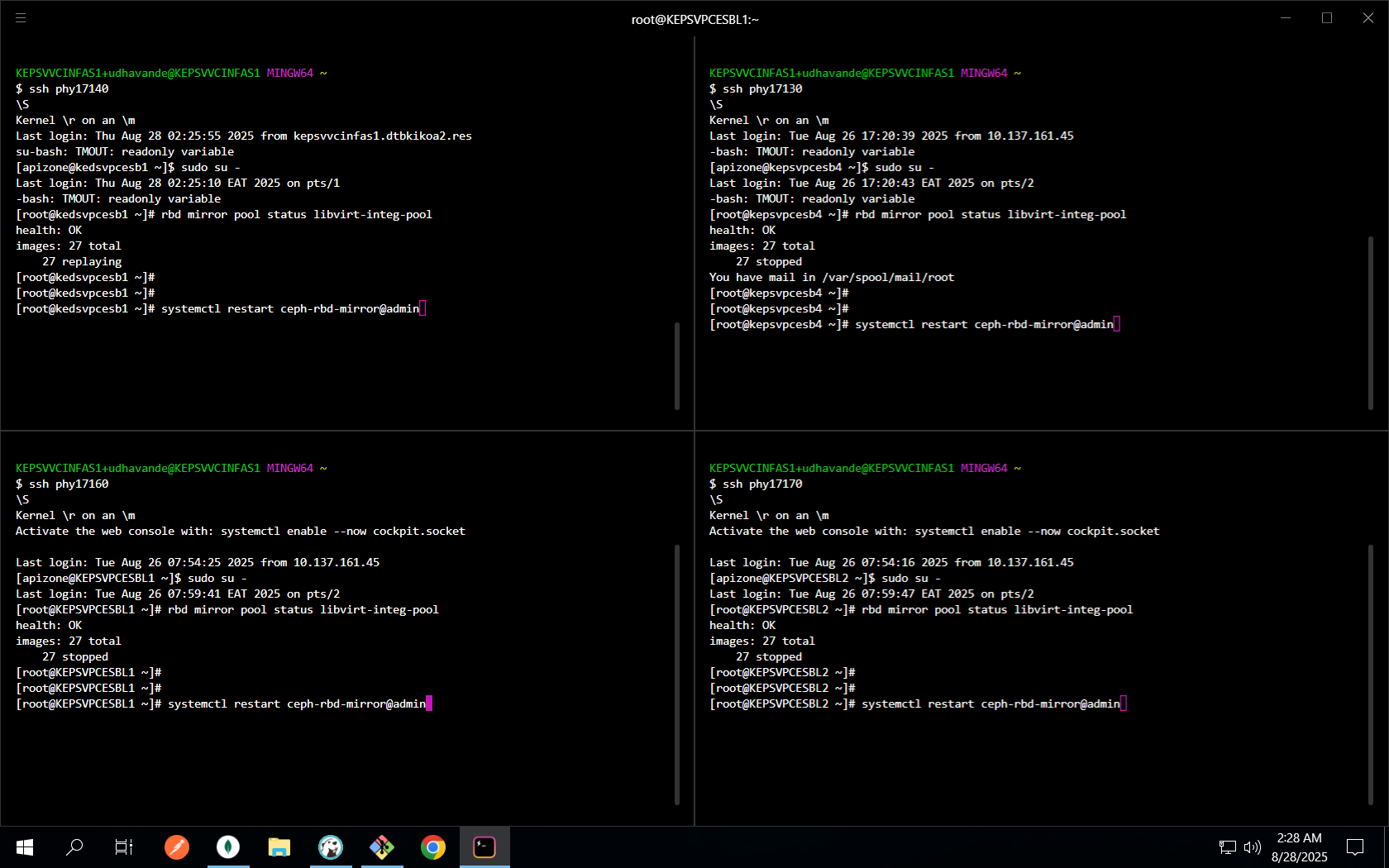
Disable jobs & monitoring
Avoid unintended writes/alerts during failover.
Crontab & Grafana & Slack bot# Disable crontab on the following: # 10.137.171.11, 10.137.171.21, 10.137.171.31, 10.0.1.150, 10.0.1.59 crontab -e # Stop Grafana on 10.137.129.57 sudo systemctl stop grafana-server sudo systemctl status grafana-server # Scale az-ext-slack to 0 (mute Slack notifications) kubectl scale --replicas=0 deploy/az-ext-slackData safety (xlsx)
Move working Excel outputs to backup to avoid partial files being read.
KE/TZ/UG paths# KE ssh cont17131 ssh mst001 ssh nod001 cd /u01/ujima_sybrin_cos mv *xlsx backup # TZ & UG ssh cont12986 ssh 10.0.1.87 cd /u02/CLUSTER_DATA_STORE/TZ/apps/ujima_sybrin_cos && mv *xlsx backup cd /u02/CLUSTER_DATA_STORE/UG/apps/ujima_sybrin_cos && mv *xlsx backup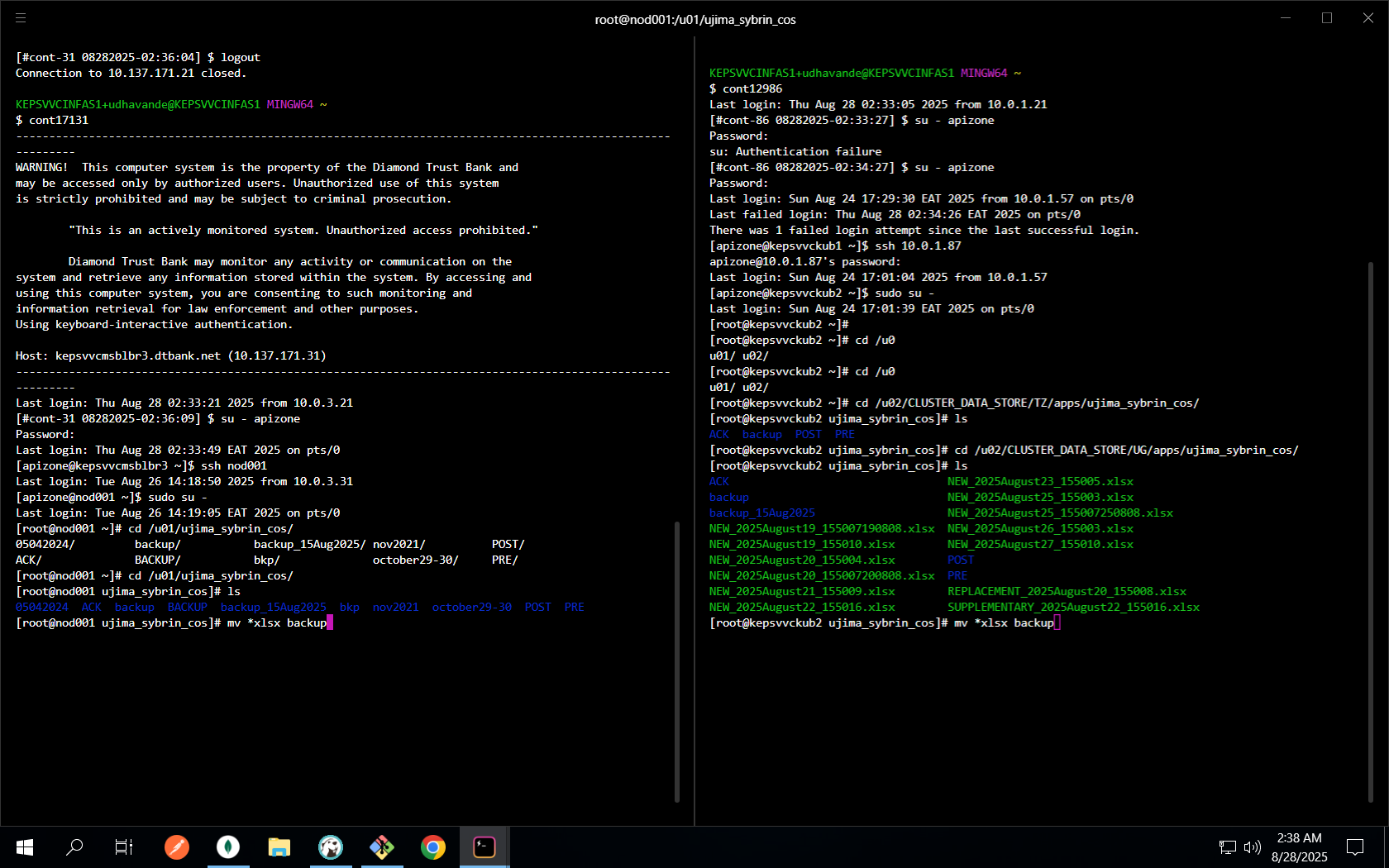
Shut down DR VMs
Cleanly stop DR guests to prevent dual-writer scenarios.
virsh destroy (DR site)virsh destroy nod001 virsh destroy nod002 virsh destroy nod003 virsh destroy mst001 virsh destroy mst002 virsh destroy mst003 virsh destroy reg001 virsh destroy nfs001 virsh destroy apm001 virsh destroy apm002 virsh destroy kepsvvcmsblbr3 virsh destroy qpid001 virsh destroy nfs001 virsh destroy kepsvvckub1 virsh destroy kepsvvckub2 virsh destroy KEPSVVCESB3-CEPH virsh destroy voyager001 virsh destroy tzpsvvcvoy01 virsh destroy ugpsvvcvoy01Check mirror image status (key images)
Ensure images are in the expected state before role switch.
Voyager/K8s/ESB & core# Voyager rbd mirror image status libvirt-integ-pool/voyager001 rbd mirror image status libvirt-integ-pool/tzpsvvcvoy01 rbd mirror image status libvirt-integ-pool/ugpsvvcvoy01 # K8s nodes & ESB rbd mirror image status libvirt-integ-pool/kepsvvckub1-disk1 rbd mirror image status libvirt-integ-pool/kepsvvckub1-disk2 rbd mirror image status libvirt-integ-pool/kepsvvckub2-disk1 rbd mirror image status libvirt-integ-pool/kepsvvckub2-disk2 rbd mirror image status libvirt-integ-pool/KEPSVVCESB3-vda rbd mirror image status libvirt-integ-pool/KEPSVVCESB3-vdb # Core guests rbd mirror image status libvirt-integ-pool/mst001 rbd mirror image status libvirt-integ-pool/mst002 rbd mirror image status libvirt-integ-pool/mst003 rbd mirror image status libvirt-integ-pool/nod001 rbd mirror image status libvirt-integ-pool/nod002 rbd mirror image status libvirt-integ-pool/nod003 rbd mirror image status libvirt-integ-pool/apm001 rbd mirror image status libvirt-integ-pool/apm002 rbd mirror image status libvirt-integ-pool/kepsvvcmsblbr3 rbd mirror image status libvirt-integ-pool/reg001 rbd mirror image status libvirt-integ-pool/qpid001 rbd mirror image status libvirt-integ-pool/nfs001 rbd mirror image status libvirt-integ-pool/nfs001-u01 rbd mirror image status libvirt-integ-pool/reg001-u01 #check if any vm pool status is behind master entries are large #if entries are behind master , stop the process , contact team lead or senior familiar with the process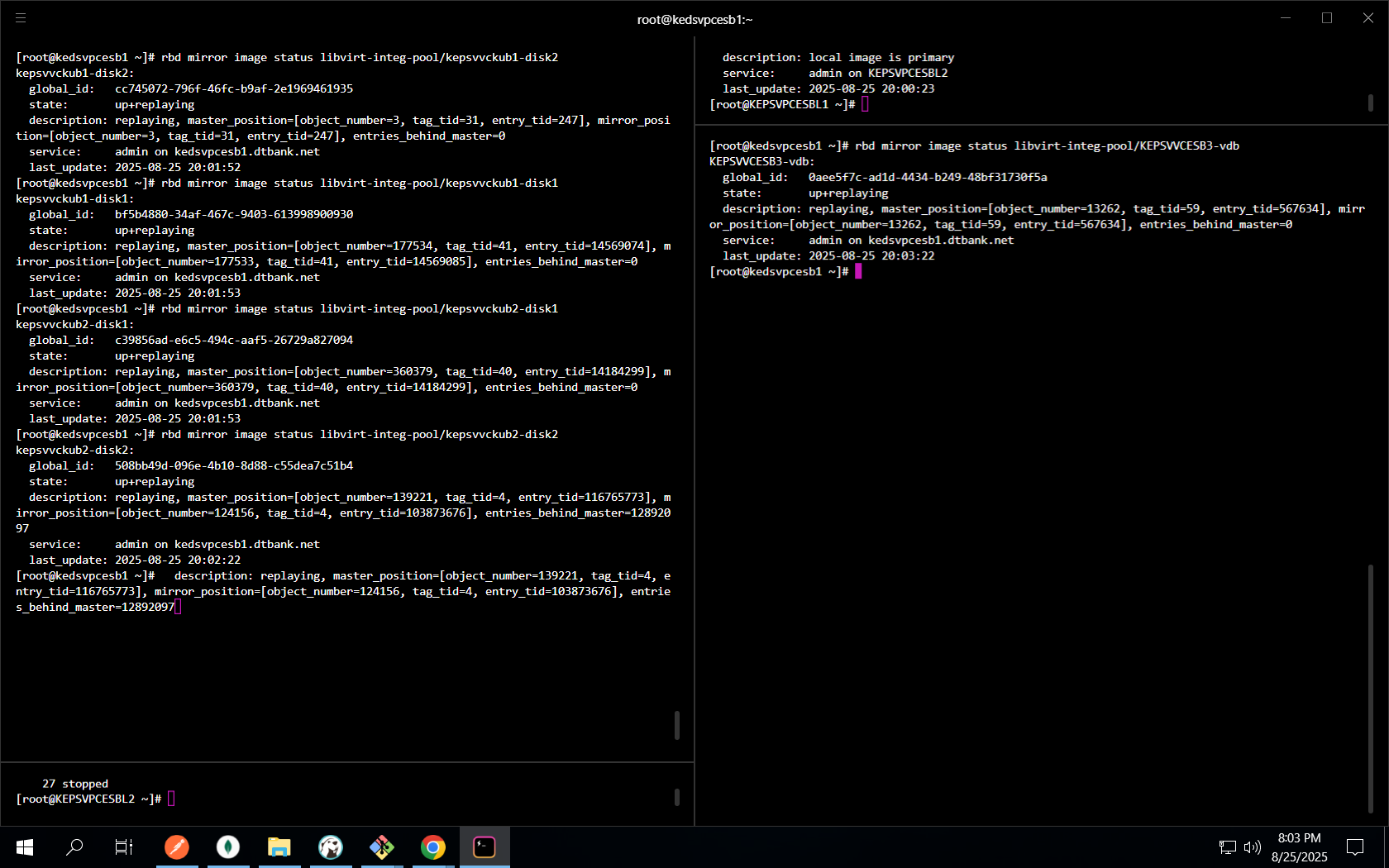
Demote images on DR
Demotion makes DR read-only so PR can be promoted safely.
rbd demote (DR)rbd mirror image demote libvirt-integ-pool/voyager001 rbd mirror image demote libvirt-integ-pool/tzpsvvcvoy01 rbd mirror image demote libvirt-integ-pool/ugpsvvcvoy01 rbd mirror image demote libvirt-integ-pool/kepsvvckub1-disk1 rbd mirror image demote libvirt-integ-pool/kepsvvckub1-disk2 rbd mirror image demote libvirt-integ-pool/kepsvvckub2-disk1 rbd mirror image demote libvirt-integ-pool/kepsvvckub2-disk2 rbd mirror image demote libvirt-integ-pool/KEPSVVCESB3-vda rbd mirror image demote libvirt-integ-pool/KEPSVVCESB3-vdb rbd mirror image demote libvirt-integ-pool/mst001 rbd mirror image demote libvirt-integ-pool/mst002 rbd mirror image demote libvirt-integ-pool/mst003 rbd mirror image demote libvirt-integ-pool/nod001 rbd mirror image demote libvirt-integ-pool/nod002 rbd mirror image demote libvirt-integ-pool/nod003 rbd mirror image demote libvirt-integ-pool/apm001 rbd mirror image demote libvirt-integ-pool/apm002 rbd mirror image demote libvirt-integ-pool/kepsvvcmsblbr3 rbd mirror image demote libvirt-integ-pool/reg001 rbd mirror image demote libvirt-integ-pool/qpid001 rbd mirror image demote libvirt-integ-pool/nfs001 rbd mirror image demote libvirt-integ-pool/nfs001-u01 rbd mirror image demote libvirt-integ-pool/reg001-u01Check mirror image status (key images)
Ensure images are in the expected state before role switch.
Voyager/K8s/ESB & core#after demote the image status should be (up+stopped / primary) # Voyager rbd mirror image status libvirt-integ-pool/voyager001 rbd mirror image status libvirt-integ-pool/tzpsvvcvoy01 rbd mirror image status libvirt-integ-pool/ugpsvvcvoy01 # K8s nodes & ESB rbd mirror image status libvirt-integ-pool/kepsvvckub1-disk1 rbd mirror image status libvirt-integ-pool/kepsvvckub1-disk2 rbd mirror image status libvirt-integ-pool/kepsvvckub2-disk1 rbd mirror image status libvirt-integ-pool/kepsvvckub2-disk2 rbd mirror image status libvirt-integ-pool/KEPSVVCESB3-vda rbd mirror image status libvirt-integ-pool/KEPSVVCESB3-vdb # Core guests rbd mirror image status libvirt-integ-pool/mst001 rbd mirror image status libvirt-integ-pool/mst002 rbd mirror image status libvirt-integ-pool/mst003 rbd mirror image status libvirt-integ-pool/nod001 rbd mirror image status libvirt-integ-pool/nod002 rbd mirror image status libvirt-integ-pool/nod003 rbd mirror image status libvirt-integ-pool/apm001 rbd mirror image status libvirt-integ-pool/apm002 rbd mirror image status libvirt-integ-pool/kepsvvcmsblbr3 rbd mirror image status libvirt-integ-pool/reg001 rbd mirror image status libvirt-integ-pool/qpid001 rbd mirror image status libvirt-integ-pool/nfs001 rbd mirror image status libvirt-integ-pool/nfs001-u01 rbd mirror image status libvirt-integ-pool/reg001-u01Promote images on PR
Promotion makes PR the active writer for each image.
rbd promote (PR)rbd mirror image promote libvirt-integ-pool/voyager001 rbd mirror image promote libvirt-integ-pool/tzpsvvcvoy01 rbd mirror image promote libvirt-integ-pool/ugpsvvcvoy01 rbd mirror image promote libvirt-integ-pool/kepsvvckub1-disk1 rbd mirror image promote libvirt-integ-pool/kepsvvckub1-disk2 rbd mirror image promote libvirt-integ-pool/kepsvvckub2-disk1 rbd mirror image promote libvirt-integ-pool/kepsvvckub2-disk2 rbd mirror image promote libvirt-integ-pool/KEPSVVCESB3-vda rbd mirror image promote libvirt-integ-pool/KEPSVVCESB3-vdb rbd mirror image promote libvirt-integ-pool/mst001 rbd mirror image promote libvirt-integ-pool/mst002 rbd mirror image promote libvirt-integ-pool/mst003 rbd mirror image promote libvirt-integ-pool/nod001 rbd mirror image promote libvirt-integ-pool/nod002 rbd mirror image promote libvirt-integ-pool/nod003 rbd mirror image promote libvirt-integ-pool/apm001 rbd mirror image promote libvirt-integ-pool/apm002 rbd mirror image promote libvirt-integ-pool/kepsvvcmsblbr3 rbd mirror image promote libvirt-integ-pool/reg001 rbd mirror image promote libvirt-integ-pool/qpid001 rbd mirror image promote libvirt-integ-pool/nfs001 rbd mirror image promote libvirt-integ-pool/nfs001-u01 rbd mirror image promote libvirt-integ-pool/reg001-u01PR bring-up — Phase 70 (rest of stack)
Bring remaining Voyager, messaging, storage, and nodes.
virsh start (remaining)virsh start tzpsvvcvoy01 virsh start qpid001 virsh start nfs001 virsh start apm002 virsh start nod003 virsh start mst003 virsh start kepsvvcmsblbr3PR bring-up — Phase 30 (foundation)
Start registry and voyager first, then core compute & ESB.
virsh start (priority set)# Initial virsh start reg001 virsh start ugpsvvcvoy01Post-failover checks
Verify cluster/node health and LB status.
Kubernetes nodes# KE cluster source ke-msb-prod kubectl get nodes -o wide # TZ cluster source tz-msb-prod kubectl get nodes -o wideHAProxy statusssh cont17131 sudo systemctl status haprxoyExpected: All nodes Ready, workloads scheduled, LB services healthy.
Re-enable services & cleanups
Once validation is green, turn automations and observability back on.
Scale Slack, start Grafana, re-enable crons# Scale az-ext-slack back kubectl scale --replicas=1 deploy/az-ext-slack # Start Grafana on 10.137.129.57 sudo systemctl start grafana-server # Re-enable crontab after failover/failback completes crontab -e # Refresh remittance pods to reload INST from DB (after completion) kubectl delete pod -n <namespace> -l app=az-prc-remittance,region=UG kubectl delete pod -n <namespace> -l app=az-prc-remittance,region=KEPlain English: put notifications back, start dashboards, re-allow scheduled jobs, and ensure remittance pods reload cleanly.
NFS mounts (debit card)
Mount required NFS shares after failover on KE & UG hosts.
mount -a on KE/UG# After failover — KE (171.11) and UG (129.57) # KE ssh cont17131 ssh 10.0.3.11 sudo mount -a # UG ssh cont12957 sudo mount -a
Rollback (high level)
- Scale down writes on PR, stop automations.
- Demote PR images, promote DR images.
- Start DR VMs in inverse order; validate.
- Re-enable jobs/monitoring on the active site.
Safety: Never have both sites promoted for the same image; always demote one side before promoting the other.Notes & tips
- Run sections in order; don’t parallelize demote/promote across pools unless validated.
- Keep a checklist of VMs/images to confirm no omissions.
- Document any deviations in a change log with timestamps.